#개념 정리
#패스트캠퍼스 강의 정리
1. isin을 활용한 색인
내가 조건을 걸고자 하는 값이 내가 정의한 list에 있을 때만 색인하려는 경우에 사용한다.

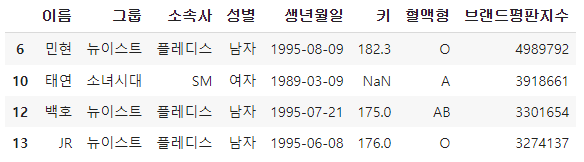
2. 결측값(Null) 알아보기
-NaN 값에 대하여
null값은 비어있는 값을 말한다.
info() 메소드를 통해 전체적으로 어떤 column에 빠진 데이터가 있는지 알 수 있다.

-NaN이 아닌 값에 대하여 Boolean 인덱싱

3. copy(복사)
copy는 dataframe을 복사할 때 사용한다.
df를 새로운 변수(new_df)에 대입해주고, 새로운 변수에서 값을 바꾸면 원래의 df의 값도 같이 바뀐다. 그 이유는 df와 new_df 모두 같은 메모리 주소를 참조하기 때문이다. 원본 데이터를 유지시키고, 새로운 변수에 복사할 때는 copy()를 사용한다.
4. row, column 추가 및 삭제
-row 추가
dictionary 형태의 데이터를 만든 다음 append() 함수를 사용하여 데이터를 추가할 수 있다. 반드시 ignore_index=True 옵션을 추가해야 에러가 나지 않는다.

그러나 tail()로 마지막 5개의 데이터를 볼 때 추가가 안된 것을 볼 수 있다. 그럴 경우, append() 한 뒤 다시 df에 대입해줘야 변경한 값이 유지가 된다.

-column 추가
새로운 column을 만들고 값을 대입하면 자동으로 생성한다. 전부 동일한 값이 추가되면서, column도 추가된 것을 볼 수 있다.

값을 변경하려면 loc 함수를 이용해 변경할 수 있다.
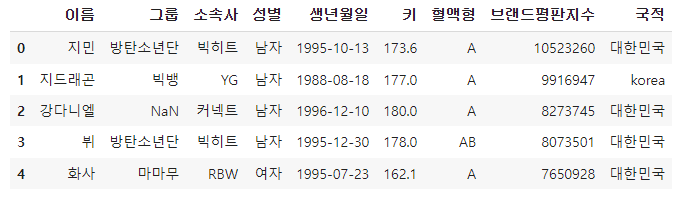
5. 통계값 다루기
통계값은 데이터 타입이 float나 int형 인 column을 다룬다.
-min, max 최대, 최소
주로 표준편차를 많이 사용하며, 데이터가 평균으로부터 얼마나 퍼져있는지 정도를 나타내는 지표이다.
-count, median, mode 개수 세기, 중앙값, 최빈값
6. 피벗테이블(pivot_table)
데이터 열 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하여 펼쳐놓은 것을 의미한다. 왼쪽에 나타나는 인덱스를 행 인덱스, 상단에 나타나는 인덱스를 열 인덱스라고 한다.

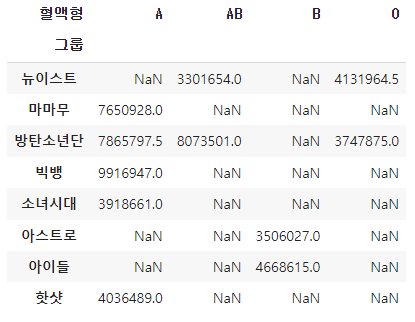
7. GroupBy
데이터를 그룹으로 묶어 분석할 때 활용한다.
8. Multi-Index(복합 인덱스)
행 인덱스를 복합적으로 구성하고 싶은 경우 인덱스를 리스트로 만들어 준다.

-피벗 테이블로 변환
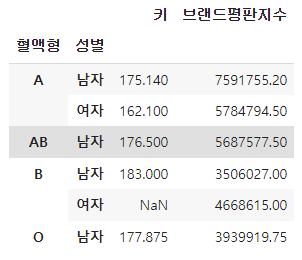
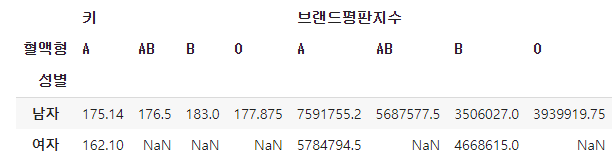
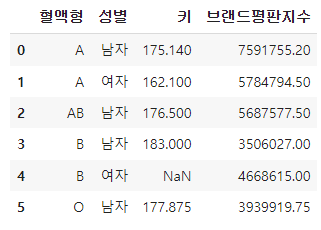
-인덱스 초기화(reset_index)
'공부 기록 > Data Analysis' 카테고리의 다른 글
| [Data/Python] 데이터분석 정리 - 4 (0) | 2022.03.19 |
|---|---|
| [Data/Python] 데이터분석 정리 - 3 (0) | 2022.03.18 |
| [Data/Python] 데이터분석 정리 - 1 (0) | 2022.03.14 |
| [Data/Python] '이것이 데이터 분석이다 with 파이썬' ch1-2 국가별 음주 데이터 분석하기 (0) | 2022.03.11 |
| [Data / Python] '이것이 데이터 분석이다 with 파이썬' ch1-1 chipotle 주문 데이터 분석하기 (0) | 2022.03.04 |