#개념 정리
#패스트캠퍼스 강의 정리
1. fillna: 결측값 na에 대하여 채워주는 함수.
키가 없는 사람은 존재할 수 없기 때문에, 데이터가 잘 못 되었다는 것을 표기하기 위해서, 누락된 데이터를 -1로 채워보도록 한다.

NaN 값이 -1로 바뀐 것을 볼 수 있다. 하지만, 키의 NaN 값을 채워준 다음 유지시키려면 inplace=True 옵션을 주거나, fillna로 채워 준 값을 다시 대입해야 한다.
2. 빈 값(NaN)이 있는 행 제거
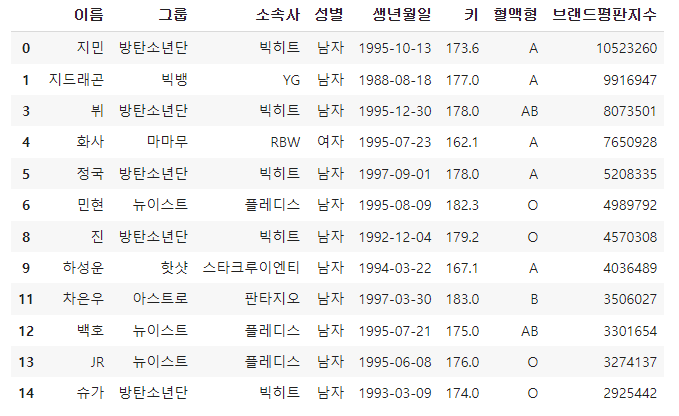
위의 행을 보면 2, 7, 10행이 사라진 것을 볼 수 있다. 또한 dropna()는 몇 가지 옵션을 추가할 수 있다.
-axis(열/행 드랍)
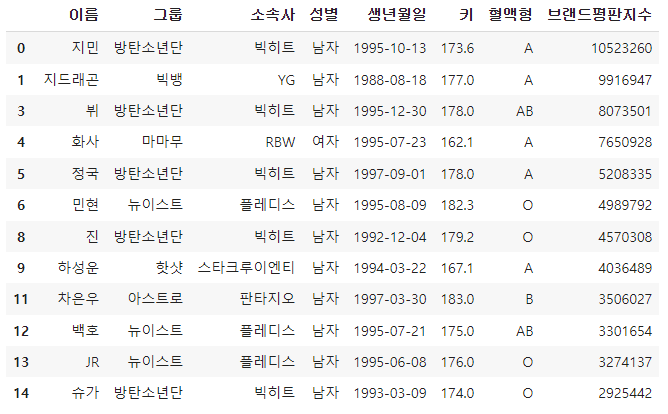
NaN값이 들어있던 행이 삭제됐다.
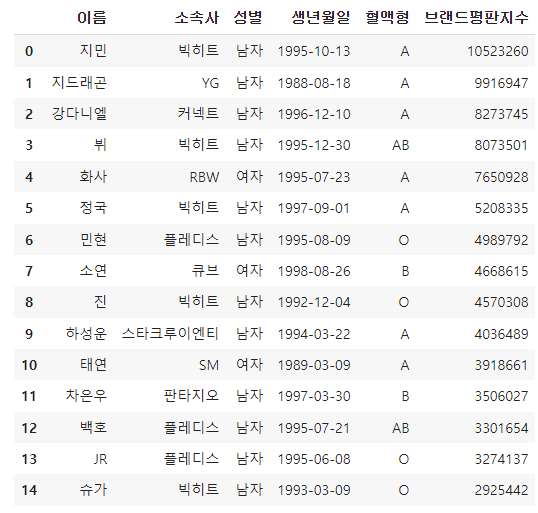
NaN값이 들어있는 열이 삭제됐다.
-how옵션 : 'any' : NaN이 한 개라도 있는 경우 삭제, 'all' : 모두 NaN인 경우 삭제



3. 중복값 제거(drop_duplicates)


-행 전체 제거

4. Drop - column/row 제거하기
-column 제거하기

-row 제거하기
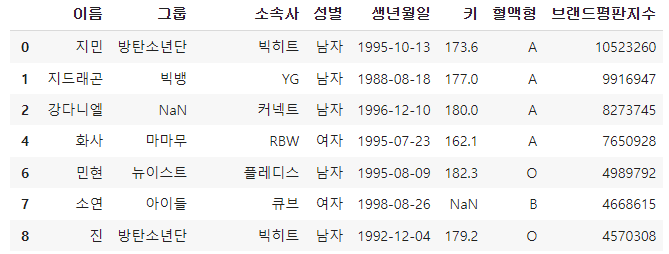
5. 데이터 프레임 합치기 (concat)
-row 기준 합치기
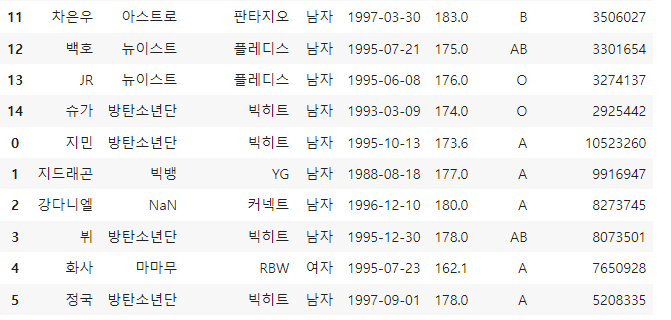
df 뒤에 바로 df_copy를 붙인 것이므로 index가 꼬인 것을 볼 수 있다. 이럴 경우 reset_index로 초기화해준다.
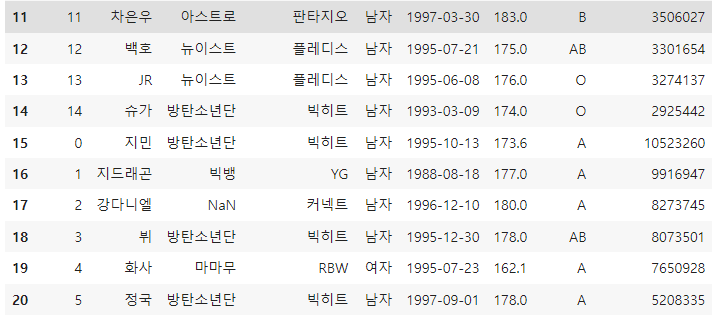
하지만, index라는 column이 추가되므로 drop=True 옵션을 추가하여 새로 index 컬럼이 생성되지 않도록 만든다.

*행의 개수가 맞지 않는 상태에서 컬럼을 concat 하면 해당 column이 없는 값에는 NaN이 들어간다.
5. 데이터프레임 병합하기 (merge)
- concat : row나 coulumn 기준으로 단순하게 이어 붙이기
- merge : 특정 고유한 키(unique id) 값을 기준으로 병합하기
pd.merge(left, right, on='기준 column', how='left')
- left와 right는 병합할 두 DataFrame을 대입합니다.
- on 에는 병합의 기준이 되는 column을 넣어 줍니다.
- how 에는 'left', 'right', 'inner', 'outer'라는 4가지의 병합 방식 중 한 가지를 택합니다.
'left' 옵션을 부여하면, left 데이터프레임에 키 값이 존재하면 해당 데이터를 유지하고, 병합한 right 데이터프레임의 값은 NaN이 대입된다.
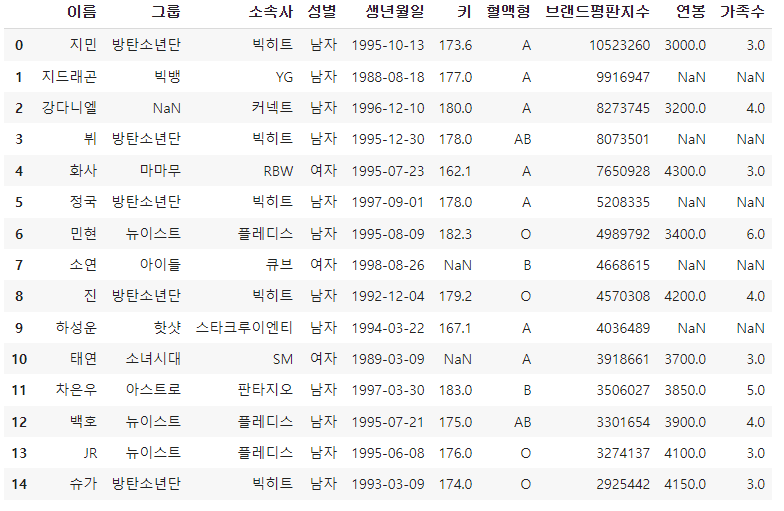
반대로 'right' 옵션을 부여하면 right 데이터프레임 기준으로 병합하게 된다. 현재, left 데이터프레임이 더 많은 데이터를 보유하고 있으니, right를 기준으로 병합하면 데이터프레임 사이즈가 줄어들게 된다.

- inner 방식은 두 DataFrame에 모두 키 값이 존재하는 경우만 병합합니다.
- outer 방식은 하나의 DataFrame에 키 값이 존재하는 경우 모두 병합합니다.
- outer 방식에서는 없는 값은 NaN으로 대입됩니다.


-column명은 다르지만, 동일한 성질의 데이터인 경우
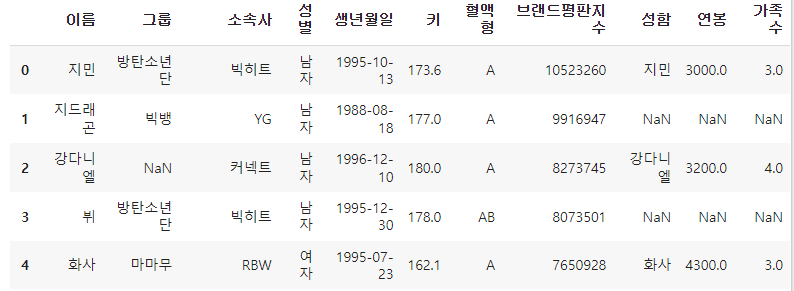
df와 df_right를 병합하려고 하지만, df에서는 '이름', df_right에서는 '성함'으로 표기되어 기준이 되는 column을 지정할 수 없다. 이럴 경우 left_on, right_on 옵션을 지정한다.
6. Series의 type
- object: 일반 문자열 타입
- float: 실수
- int: 정수
- category: 카테고리
- datetime: 시간
-type 변환하기 : astype메서드 사용
키 column의 타입 float를 int 타입으로 변경해보자

그러나 NaN의 값이 있기 때문에 에러가 발생한다. 이럴 경우 fillna로 빈 값을 -1로 채운다.

float -> int로 변경되었다.
-날짜 변환하기 (datetime 타입)
날짜를 변환하기 위해 판다스 메서드인 to_datetime이라는 메서드를 사용한다.
현재 날짜 column은 dtype:이 object, 즉 문자열 타입으로 되어 있다.


dtype이 datetime으로 변환되었다. 하지만 데이터 프레임에는 반영되지 않으므로 변환된 것을 df ['날짜'] column에 다시 대입을 해야 정상적으로 변환된 값이 들어간다.

datetime 타입으로 변환해야 하는 이유>
- 매우 손쉽게, 월, 일, 요일 등등의 날짜 정보를 세부적으로 추출해낼 수 있다.
- datetime의 약어인 'dt'에는 다양한 정보들을 제공해 준다.
7. apply
series나 dataframe에 좀 더 구체적인 로직을 적용하고 싶을 경우 활용한다.
- apply를 적용하기 위해서는 함수가 먼저 정의되어야 한다.
- apply는 정의한 로직 함수를 인자로 넘겨준다.


8. lambda 함수
- lambda는 1줄로 작성하는 간단 함수 식이다.
- return을 별도로 명시하지 않는다.

실제로는 간단한 계산식을 적용하려는 경우에 많이 사용한다. apply에 함수 식을 만들어서 적용하는 것과 동일하기 때문에, 복잡한 조건식은 함수로 간단한 계산식은 lambda로 적용할 수 있다.
9. map()

'공부 기록 > Data Analysis' 카테고리의 다른 글
| [Data/Python] 데이터분석 정리 - 5 (0) | 2022.03.22 |
|---|---|
| [Data/Python] 데이터분석 정리 - 4 (0) | 2022.03.19 |
| [Data/Python] 데이터분석 정리 - 2 (0) | 2022.03.15 |
| [Data/Python] 데이터분석 정리 - 1 (0) | 2022.03.14 |
| [Data/Python] '이것이 데이터 분석이다 with 파이썬' ch1-2 국가별 음주 데이터 분석하기 (0) | 2022.03.11 |