Chapter 01 데이터에서 인사이트 발견하기
1-2. 국가별 음주 데이터 분석하기
step1 탐색 : 데이터의 기초 정보 살펴보기
이번 데이터셋을 이루고 있는 피처는 다음과 같다.
- country: 국가정보
- beer_servings: beer 소비량
- spirit_servings: spirit 소비량
- wine_servings: wine 소비량
- total_litres_of_alcohol: 총 알코올 소비량
- continent: 국가의 대륙 정보
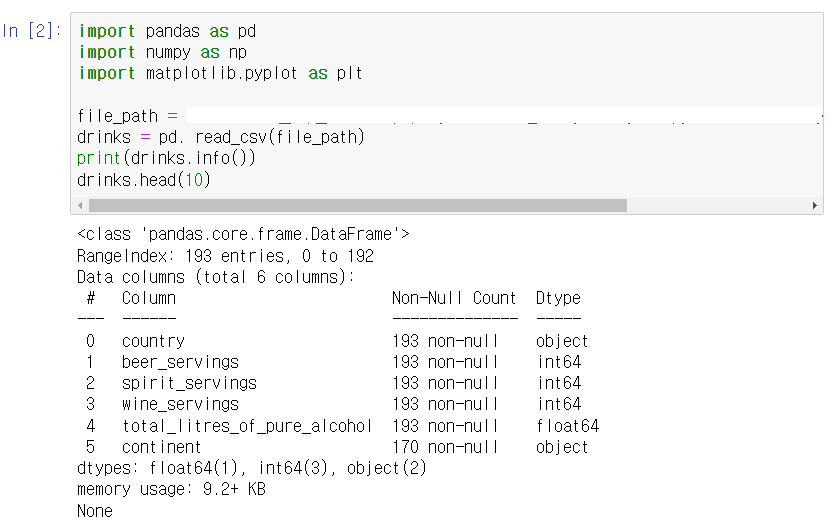
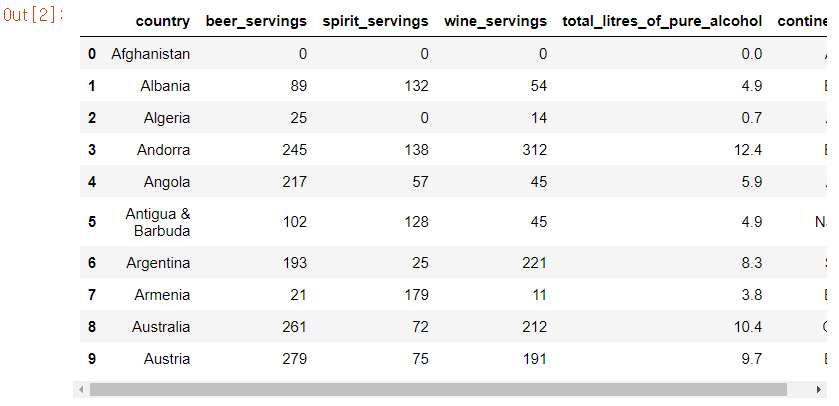
info() 함수로 데이터의 기초적인 정보를 살핀다. 총 193개의 데이터가 있으며, country와 continent를 제외한 피처들은 수치형 피처로 구성되어 있고, countinent 피처는 23개의 결측값이 존재한다.
step2 인사이트의 발견: 탐색과 시각화하기
피처 간의 상관관계를 통계적으로 탐색하는 방법은 크게 두 가지이다. 첫 번째 방법은 피처가 2개일 때 상관 계수를 계산하는 단순 상관 분석 방법이며, 두 번째 방법은 대상 피처가 여러 개 일 때 상호 간의 연관성을 분석하는 다중 상관 분석이다.
*상관분석이란?
두 변수 간의 선평적 관계를 상관 계수로 표현하는 것이다. 상관 계수를 구하는 것은 공분산의 개념을 포함한다. 공분산은 2개의 확률 변수에 대한 상관 정도로, 2개의 변수 중 하나의 값이 상승하는 경향을 보일 때 다른 값도 상승하는 경향을 수치로 나타낸 것. 하지만 공분산만으로 두 확률 변수의 상관관계를 구한다면 두 변수의 단위 크기에 영향을 받을 수 있다. 따라서 이를 -1과 1 사이의 값으로 변환한다.
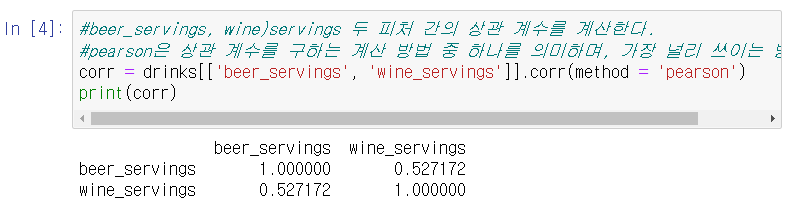
먼저 맥주와 와인 소비량의 상관관계를 알아보자. 아래 코드처럼 데이터 프레임에서 두 피처를 선택한 뒤, corr() 함수를 적용한다. 이를 통해 피처 간의 상관 계수를 matrix의 형태로 출력할 수 있다.
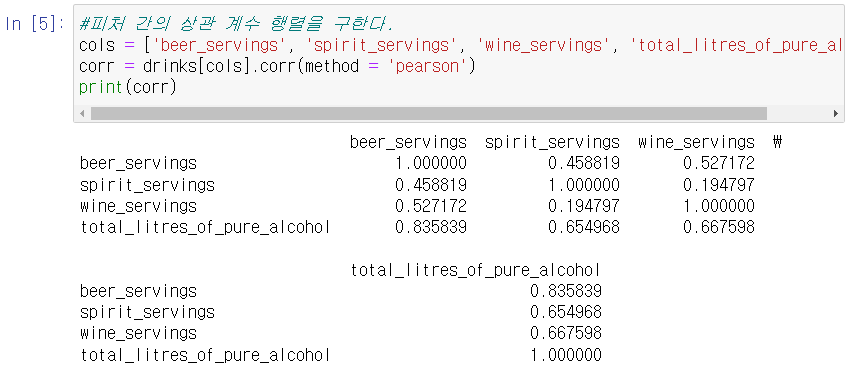
이를 조금 더 쉽게 실행하기 위해 'heatmap', 'pairplot'이라는 기법을 사용해보자. 파이썬의 seaborn이라는 시각화 라이브러리를 활용하여 이 2개 기법을 사용할 수 있다. 코드는 매우 간단하다. heatmap의 경우 corr.values를, pairplot의 경우 데이터 프레임을 파라미터로 넣어준다.

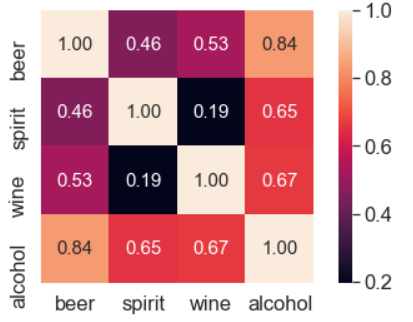
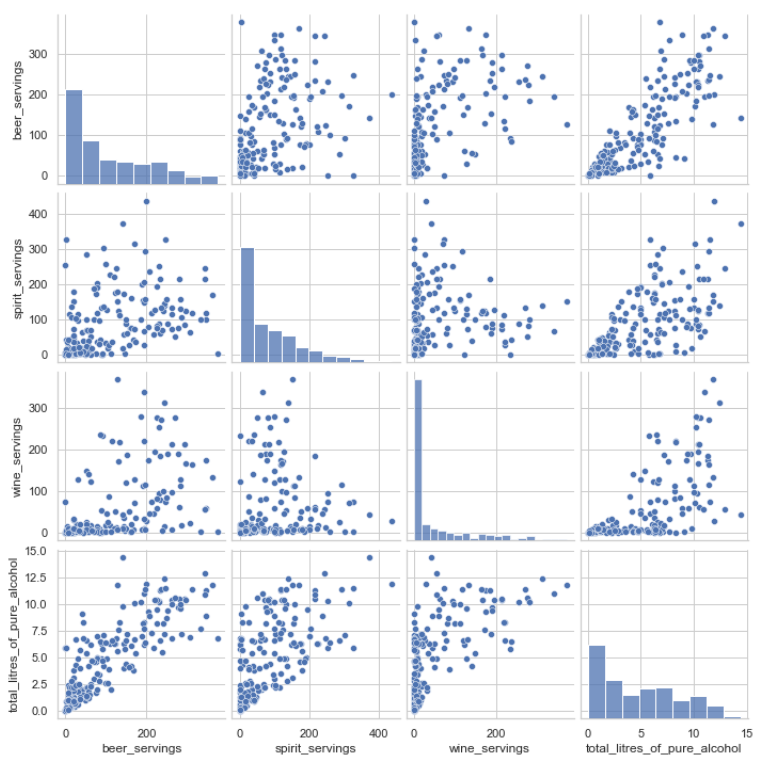
위 두 그래프를 살펴보면 total_litres_of_pure_alcohol 피처가 대체적으로 모든 피처와 상관관계가 있는 것으로 보이며, 특히 beer_servings와의 상관성이 매우 높은 것으로 나타난다. 첫 번째 그래프가 heatmap그래프, 두 번째 그래프가 pairplot 그래프이다.
step3 탐색적 분석: 스무고개로 개념적 탐색 분석하기
continent 피처에 존재하는 결측 데이터를 처리해보자. fillna() 함수를 사용하여 drinks 데이터 프레임의 continent 피처의 결측값을 OT로 채워준다.
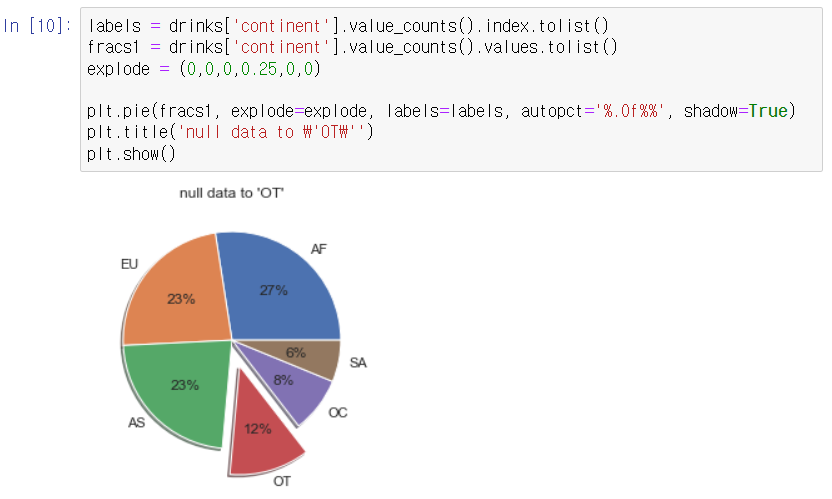
이번에는 전체 대륙 중에서 OT가 차지하는 비율이 얼마나 되는지를 파이 차트로 확인해보자. 아래 코드는 plt.pie() 함수를 이용한 파이 차트 출력 방법이다.
대륙별 spirit_servings의 통계적 정보는 어느 정도일까?
agg() 함수를 사용하여 대륙 단위로 분석을 수행한다. agg() 함수는 apply() 함수와 거의 동일한 기능을 하지만, apply()에 들어가는 함수 파라미터를 병렬로 설정하여 그룹에 대한 여러 가지 연산 결과를 동시에 얻을 수 있는 함수이다. 대륙별 'spitit_servings'의 통계적 정보를 구하기 위해서는 agg에 ['mean', 'min', 'max', 'sum'] 파라미터를 입력하는 것만으로도 간단히 탐색이 가능하다.
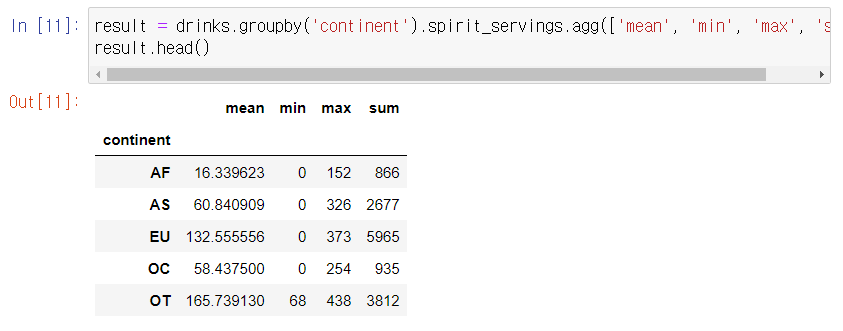
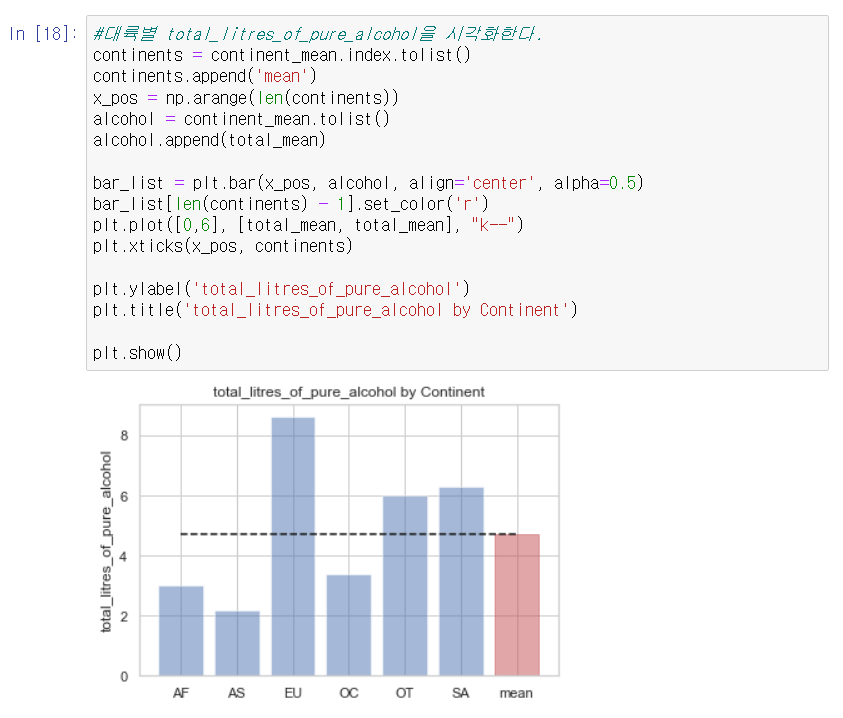
전체 평균보다 많은 알코올을 섭취하는 대륙은 어디일까?
apply()나 agg() 함수 없이도 mean() 함수만을 이용한 탐색을 수행할 수 있다.

평균 beer_servings가 가장 높은 대륙은 어디일까?
mean() 함수만을 이용한 탐색에 idxmax() 함수를 적용하면 평균 'beer_servings'가 가장 높은 대륙이 어디인지 찾을 수 있다. idxmax()는 시리즈 객체에서 값이 가장 큰 index를 반환하는 기능을 수행한다.

시각화


step4 통계적 분석: 분석 대상 간의 통계적 차이 검정하기
분석 결과에 타당성을 부여하기 위해 통계적으로 차이를 검정하는 과정이 필요하다. 그중 가장 기본적인 방법인 t-test를 통해 분석 대상 간에 통계적 차이를 검정하는 방법을 알아보자.
*t-test란
두 집단 간 평균의 차이에 대한 검정 방법으로, 모집단의 평균 등과 같이 실제 정보를 모를 때 현재의 데이터만으로 두 집단의 차이에 대해 검정할 수 있는 방법이다. 단, t-test는 검정 대상인 두 집단의 데이터 개수가 비슷하면서 두 데이터가 정규 분포를 보이는 경우에 신뢰도가 높은 검정 방식이다.
파이썬에서는 scipy라는 라이브러리를 활용하여 두 집단 간의 t-test를 검정할 수 있다. ttest_ind() 함수에 두 집단의 시리즈 데이터를 넣는 것으로 검정의 결과를 확인할 수 있는데, 이 함수의 파라미터인 equal_var는 t-test의 두 가지 방법 중에 하나를 선택하는 것이다. 첫 번째는 두 집단의 분산이 같은 경우, 그리고 두 번째는 두 집단의 분산이 같지 않은 경우를 가정한 것이다.

실행 결과에 등장하는 t-statistic은 t-test의 검정 통계량으로, 함께 출력하는 p-value와 연관 지어 해석해야 한다. p-value는 가설이 얼마나 믿을만한 것인지를 나타내는 지표로, 데이터를 새로 샘플링했을 때 귀무가설이 맞다는 전제 하에 현재 나온 통계값 이상이 나올 확률이라고 정의할 수 있다. 만약 p-value가 너무 낮으면 귀무가설이 일어날 확률이 너무 낮기 때문에 귀무가설을 기각하게 된다. 보통 그 기준은 0.05나 0.01을 기준으로 하며, 이를 p-value(유의 확률)이라고 한다. 귀무가설이란 처음부터 버릴 것을 예상하는 가설이며, 가설이 맞지 않다는 것을 증명하기 위해 수립하는 가설이다. 그리고 반대되는 것을 대립 가설이라 부르며, 귀무가설이 거짓인 경우에 대안적으로 참이 되는 가설을 의미한다.
다음 '대한민국은 얼마나 독하게 술을 마시는 나라일까?'에 대한 탐색 코드를 살펴보자. 이를 판단하는 기준으로, alcohol_rate 피처를 생성한다. 이 피처는 total_litres_of_pure_alcohol 피처를 모든 술의 총소비량으로 나눈 것이다. 그리고 alcohol_rate는 sort_values() 함수를 사용하여 국가를 기준으로 정렬한다.

이 결과를 토대로 시각화를 수행한 결과는 다음과 같다. x_pos = np.arrange(len(country_list))를 통해 그래프의 x축에 해당하는 범위를 생성하고, rank = country_with_rank.alcohol_rate.tolist()를 통해 alcohol_rate순으로 정렬된 데이터에서 alcohol_rate 값을 생성하였다.

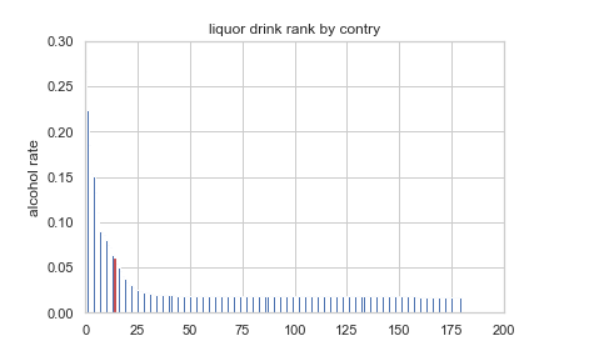
출처 : 이것이 데이터 분석이다 with 파이썬
'공부 기록 > Data Analysis' 카테고리의 다른 글
| [Data/Python] 데이터분석 정리 - 3 (0) | 2022.03.18 |
|---|---|
| [Data/Python] 데이터분석 정리 - 2 (0) | 2022.03.15 |
| [Data/Python] 데이터분석 정리 - 1 (0) | 2022.03.14 |
| [Data / Python] '이것이 데이터 분석이다 with 파이썬' ch1-1 chipotle 주문 데이터 분석하기 (0) | 2022.03.04 |
| [Data / Python] '이것이 데이터 분석이다 with 파이썬' ch.00 (0) | 2022.03.02 |