Chapter 01 데이터에서 인사이트 발견하기
1-1. 멕시코풍 프랜차이즈 chipotle의 주문 데이터 분석하기
step1 탐색 : 데이터의 기초 정보 살펴보기
데이터를 불러오기 위해서 read_csv() 함수를 사용하여 데이터 파일의 경로를 입력한다. 데이터 파일의 경로를 의미하는 변수는 file_path이며, 사용자가 데이터를 저장한 파일 경로를 입력한다.

그리고 shape()와 info() 함수를 호출하면 위와 같은 실행 결과를 볼 수 있다. shape()는 데이터의 행과 열의 크기를 반환하고, info()는 행의 구성 정보와 열의 구성 정보를 나타낸다. 실행 결과를 보면 데이터가 4,622개의 행과 5개의 피처로 구성되어 있다. 또한 orer_id와 quantity는 int64(숫자), 나머지 3개의 피처는 object라는 타입으로 이루어져 있다는 것을 알 수 있다. 한 가지 특이한 정보는 choice_description 피처가 3,376개의 non-null object로 구성되어 있다. 이는 무엇을 의미하는 것일까?
데이터 프레임에서 object 타입은 일반적으로 문자열의 의미한다. 그리고 null이라는 용어는 데이터가 비어 있는 것을 의미한다. 이를 결측값이라고 한다. 즉 '3376 non-null object'라는 것은 3,376개의 비어있지 않은 문자열 데이터가 있다는 정보이다. 하지만 데이터의 개수는 4,622개이므로 choice_description 피처는 1,246개의 결측값이 존재한다.

위 코드는 columns(행의 목록)와 index(열의 목록)를 호출하면 데이터의 행과 열에 대한 정보를 함께 출력할 수 있다.
quantity와 item_price의 수치적 특징
두 피처는 연속형 피처이다. 연속형 피처는 키와 몸무게처럼 어떠한 값도 가질 수 있는 연속적인 숫자 형태를 의미한다.
다음 코드의 출력 결과는 describe() 함수가 나타낸 피처의 기초 통계량이다. 하지만 현재 유일하게 존재하는 수치형 피처는 quantity뿐이기 때문에, 오직 quantity에 대한 정보만을 출력할 수 있다.

출력 내용을 분석하면 아이템의 평균 주문 수량(mean)은 약 1.07이라는 것을 알 수 있다. 이는 대부분이 한 아이템에 대해서 1개 정도만 주문했다는 것이고, '한 사람이 같은 메뉴를 여러 개 구매하는 경우는 많지 않다'는 인사이트를 얻을 수 있다.
그렇다면 item_price의 수치적 특징은 어떻게 알아볼까? 현재 item_price 피처는 object 타입이기 때문에 describe() 함수로 기초 통계량을 확인할 수 없다. 이를 위해서는 추가적인 데이터 전처리 작업이 필요한데, 이는 'step3 데이터 전처리'에서 알아볼 것이다.
orer_id와 item_name의 개수
이 두 피처는 범주형 피처이기 때문에 unique() 함수를 사용한다. 이를 통해 피처 내에 몇 개의 범주가 있는지를 확인 할 수 있다.

step2 인사이트 발견: 탐색과 시각화하기
가장 많이 주문한 아이템 Top 10
가장 많이 주문한 아이템 Top 10을 분석하기 위해 다음과 같이 DataFrame ['column']의 형태에 value_counts() 함수를 적용하는 방식을 사용한다. DataFrame [columns']은 시리즈라는 객체를 반환하는데, value_counts() 함수는 오로지 이러한 시리즈 객체에만 적용되기 때문이다.

아이템별 주문 개수와 총량
이번에는 groupby() 함수를 이용하여 아이템별 주문 개수와 총량을 구해보자. 판다스의 groupby() 함수는 데이터 프레임에서 특정 피처를 기준으로 그룹을 생성하며 이를 통해 그룹별 연산을 적용할 수 있다. 예를 들어 '학급'이라는 그룹을 만들었을 때, '학급별 평균 키', '학급별 평균 몸무게'등을 구분하는 것처럼 말이다.

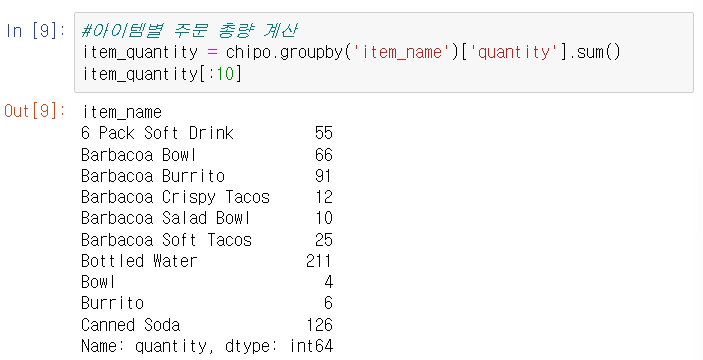
위의 코드 chipo.groupby('item_name')['order_id']. count()는 chipo Dataf에서 item_name을 그룹으로 order_id 피처의 count()를 계산한 것이다. 이는 아이템별 주문 개수를 의미하고 마찬가지 방법으로 chipo.groupby('item_name' ['quantity']. sum()은 아이템별 주문 총량을 나타낸다.
시각화
아이템별 주문의 총량을 막대그래프로 시각화할 수 있다. tolist()와 넘파이의 arrange() 함수를 이용해 x_pos를 선언하고, 0부터 50까지의 숫자를 그래프의 x축 이름으로 사용한다. 그 이유는 50개 아이템의 이름을 x축에 표현하기에는 그래프의 공간이 너무 협소하기 때문이다. y값(order_cnt)에는 주문 총량에 해당하는 값인 item_quantity.values.tolist()를 넣어준다.

step3 데이터 전처리: 전처리 함수 사용하기
앞선 내용의 item_price의 수치적 특징을 탐색하는 과정에서 우리는 item_price 피처의 요약 통계를 구할 수 없었다. 이는 item_price 피처가 문자열 타입이었기 때문이다. 이번 단계에서 이러한 데이터를 전처리하는 법을 알아보자.

출력 결과 가격을 나타내는 숫자 앞에 '$' 기호가 붙어는 것을 발견할 수 있다. 따라서 이 피처를 수치 데이터로 사용하기 위해서는 '$' 기호를 제거해주는 전처리 작업이 필요하다.
'$' 기호를 제거하는 전처리 방법은 chipo ['item_price']에 apply() 함수를 적용함으로써 가능하다. 그리고 apply() 함수에는 lambda라는 함수 명령어를 추가해준다.

apply() 함수는 시리즈 단위의 연산을 처리하는 기능을 수행하며, sum()이나 mean()과 같이 연산이 정의된 함수를 파라미터로 받는다. 따라서 피처 단위의 합계나 평균을 구할 수도 있고, 우리가 정의할 새로운 함수 문자열 데이터에서 첫 번째 문자열을 제거한 뒤 나머지 문자열을 수치형으로 바꿔주는 함수를 파라미터로 입력할 수도 있다. 위의 코드 lamda x: float (x [1:])는 이를 수행하는 함수를 lambda로 정의하여 입력한 것이다.
step4 탐색적 분석: 스무고개고 개념적 탐색 분석하기
주문당 평균 계산금액 출력하기
다음 코드는 order_id로 그룹을 생성한 뒤, item_price 피처에 sum() 함수를 적용하고 mean() 함수를 추가한 것이다. 이를 통해 주문당 평균 계산금액을 구할 수 있다. 실행 결과, 한 사람이 '약 18달러가량의 주문을 할 것'이라는 인사이트를 얻을 수 있다.

한 주문에 10달러 이상 지불한 주문 번호(id) 출력하기
order_id 피처(하나의 주문)를 기준으로 그룹을 만들어 quantity, item_price 피처의 합계를 계산한다. 그리고 이 결과에서 10 이상인 값을 필터링한다. 이에 대한 최종 결과인 results의 index.values를 출력하면 한 주문에 10달러 이상 지불한 id를 출력할 수 있다.

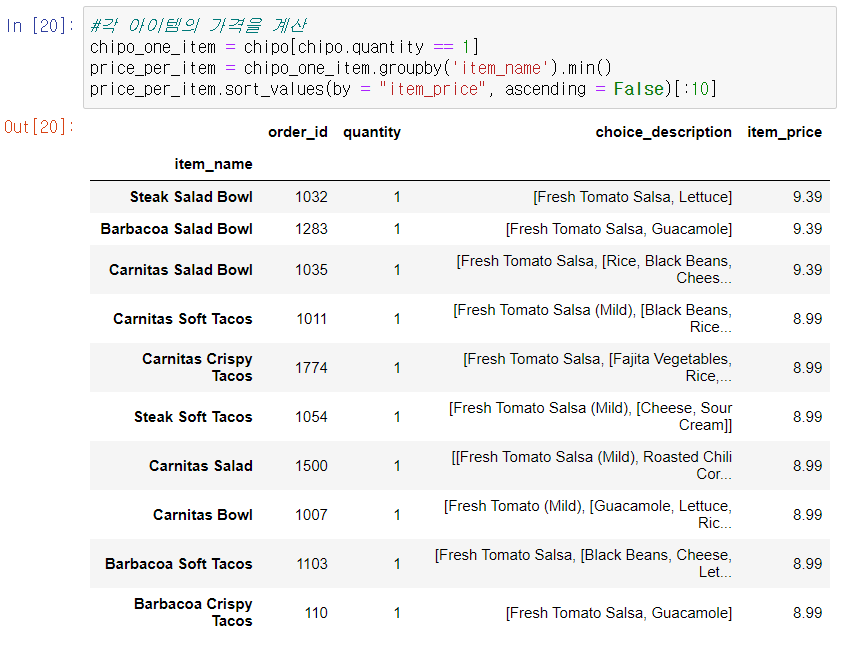
각 아이템의 가격 구하기
chipotle 데이터셋에서는 주어진 데이터만으로 각 아이템의 가격을 대략적으로 유추해야 한다. 유추 과정은 다음과 같다.
- chipo [chipo.quantity == 1]으로 동일 아이템을 1개만 구매한 주문을 선별한다.
- item_name을 기준으로 groupby 연산을 수행한 뒤, min() 함수로 각 그룹별 최저가를 계산한다.
- item_price를 기준으로 정렬하는 sort_values() 함수를 적용한다. sort_values()는 series 데이터를 정렬해주는 함수이다.
그리고 각 아이템의 대략적인 가격을 아래와 같이 2개의 그래프로 시각화하여 나타낼 수 있다. 각각의 그래프는 아이템의 가격 분포와 가격 히스토그램을 나타낸다. 이를 통해 2~4달러, 혹은 6~8달러 정도에 아이템의 가격대가 형성되어 있음을 알 수 있다.


가장 비싼 주문에서 아이템이 총 몇 개 팔렸는지 구하기
이 질문에서도 마찬가지로, order_id에 그룹별 합계 연산을 적용한다. 그리고 item_pricce를 기준으로 sort_values를 변환하면 가장 비싼 주문 순으로 연산 결과를 얻을 수 있다. 다음 결과에서는 가장 비싼 주문에서 23개의 아이템을 주문한 것을 알 수 있다.

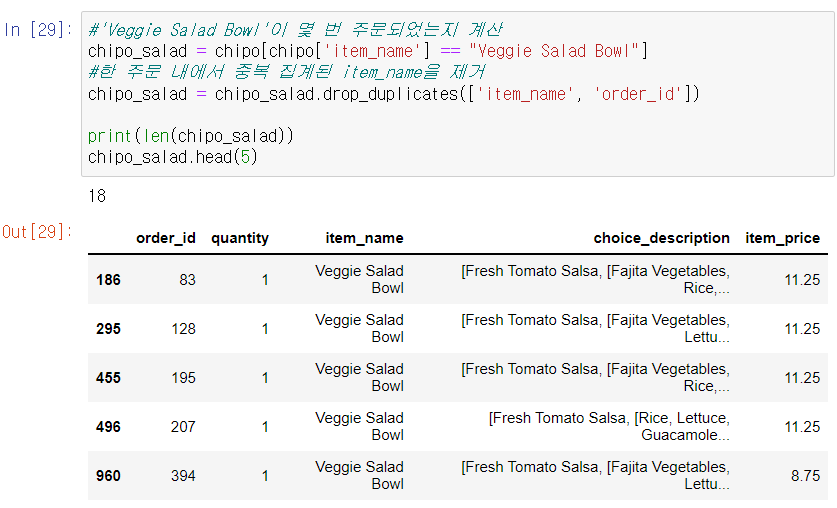
'Veggie Salad Bowl'이 몇 번 주문되었는지 구하기
이를 위해 chipo [chipo ['item_name'] == "Veggie Salad Bowl"]으로 필터링한 뒤, drop_duplicates()라는 함수를 사용한다. 이는 한 주문 내에서 item_name이 중복 집계된 경우를 제거해주기 위함이다.
그리고 최종 결과인 chipo_Salad의 길이를 출력하면 Veggie Salad Bowl이 데이터 내에서 몇 번이나 주문되었는지 구할 수 있다. 출력 결과, Veggie Salad Bowl은 총 18번 주문된 것을 알 수 있다.
'Chicken Bowl'을 2개 이상 주문한 주문 횟수 구하기
먼저 'Chicken Bowl'을 주문한 데이터만을 필터링한 뒤, 데이터 프레임에서 quantity가 2 이상인 것을 선택하면 이 결과가 'Chicken Bowl'을 2개 이상 주문한 주문 횟수를 의미한다. 2개 이상으로 필터링을 적용한 출력 결과는 다음과 같다.

출처 : 이것이 데이터 분석이다 with 파이썬
'공부 기록 > Data Analysis' 카테고리의 다른 글
| [Data/Python] 데이터분석 정리 - 3 (0) | 2022.03.18 |
|---|---|
| [Data/Python] 데이터분석 정리 - 2 (0) | 2022.03.15 |
| [Data/Python] 데이터분석 정리 - 1 (0) | 2022.03.14 |
| [Data/Python] '이것이 데이터 분석이다 with 파이썬' ch1-2 국가별 음주 데이터 분석하기 (0) | 2022.03.11 |
| [Data / Python] '이것이 데이터 분석이다 with 파이썬' ch.00 (0) | 2022.03.02 |